
Introduzione
In questa serie di documenti riporto un sunto dei concetti fondamentali che stanno alla base del sistema operativo Unix e degli altri sistemi operativi che ad esso si ispirano. Questi documenti sono una rielaborazione delle dispense alle lezioni su questo argomento, e sono destinati a sistemisti e utenti che devono operare in questo ambienteLe origini del sistema operativo Unix. Cenni storici e situazione attuale.
Cenni storici
Nel 1965 la General Electric, monopolista dell'energia elettrica negli USA e uno dei principali clienti dei costruttori di computer, si pone il problema di ridurre i costi della gestione delle macchine e della loro programmazione: occorreva un sistema operativo comune sia per l'uso sia per lo sviluppo del software
, in modo da semplificare la condivisione di dati e programmi. Viene interessato del problema il centro ricerche Bell Laboratories, il prestigioso istituto finanziato dalla AT&T.MULTICS. Tutti i ricercatori dei laboratori Bell che si interessavano di informatica vennero presto coinvolti nel progetto: il nuovo sistema operativo doveva girare su una moltitudine di hardware diversi di diversi costruttori, doveva supportare la multiutenza e la multiprogrammazione, doveva supportare processi multipli in esecuzione contemporanea ed essere multi-pourpuse: il nome scelto per questo progetto fu perciò MULTICS. In questo progetto i ricercatori cercarono di esprimere il massimo delle tecnologie informatiche dell'epoca, e il sistema assunse ben presto dimensioni e complessità ai limiti delle possibilità delle macchine disponibili.
UNIX. Dopo alcuni anni di sviluppo, divenne chiaro che il progetto era troppo ambizioso, e le funzionalità previste di MULTICS troppo difficili da implementare, e i ricercatori coinvolti cominciarono a considerare soluzioni alternative. Tra questi, Dennis Ritchie e Ken Thompson proposero un sistema ridotto all'essenziale, traendo dal progetto MULTICS solo gli aspetti che sembravano loro indispensabili. Ne nacque un sistema più snello, meno ambizioso ma più pratico: lo chiamarono UNIX (il nome pare che sia stato suggerito da Brian Kernighan, successivamente coinvolto nello sviluppo del linguaggio C).
Ottenuta l'approvazione dei laboratori Bell, nel 1969 Ritchie e Thompson iniziarono la scrittura del nuovo sistema operativo su di un computer Digital PDP-7 e nell'arco di un paio di anni il sistema divenne funzionante e stabile: una unità di processo a 16 bit grande come un frigorifero, una memoria RAM di 384 KB a nuclei di ferrite e due telescriventi permettevano a due operatori di lavorare sul sistema in contemporanea.
Linguaggio C. La scrittura del kernel di Unix avveniva ancora in linguaggio assembly: la stesura del codice e il suo debugging era perciò molto laboriosa. Per velocizzare il lavoro, decisero di utilizzare un linguaggio di programmazione di più alto livello e in grado di generare codice ottimizzato dalle prestazioni paragonabili al codice assembly. Dopo vari perfezionamenti, il linguaggio venne chiamato C, e già il nome è indice della sua stringatezza. Quasi tutto il kernel e tutti i programmi di sistema vennero riscritti in C e compilati per ottenere il codice macchina eseguibile. Un altro vantaggio di questa scelta fu che il trasporto del sistema su nuove macchine veniva enormemente facilitato: per generare il sistema su di un nuovo computer bastava istruire il compilatore C per generare il codice specifico di quella macchina, dopo di ché i sorgenti del sistema operativo Unix potevano esser compilati.
In virtù della sua natura di progetto di ricerca, il laboratorio Bell scelse di distribuire gratuitamente i sorgenti di Unix presso le università e gli altri istituti di ricerca sparsi nel mondo: così ben presto Unix diventò disponibile su una varietà di macchina diverse, e con esso si diffondeva anche il C come linguaggio di riferimento per il software di sistema realizzato in questo ambiente.
Nel 1974 il progetto Unix aveva raggiunto la sua maturità, e cominciavano a moltiplicarsi anche le installazioni per uso aziendale, oltre che per uso di ricerca. Ad indicare questa maturità raggiunta, i Bell Labs registrarono il marchio Unix e pacchetizzarono il prodotto con il nome di Unix System III, sebbene non siano mai esistiti un System II o un System I.
La famiglia cresce. Dagli originali sorgenti in circolazione per il mondo, presero anche a moltiplicarsi varianti sul tema: praticamente ogni costruttore di computer realizzò una propria implementazione di Unix: i nomi di questi sistemi operativi, per ragioni di marchio, ereditarono da Unix almeno la U e la X e sono facilmente riconoscibili.
Nel 1984, a seguito della applicazione delle norme antitrust, il governo USA decise per lo scorporamento dalla AT&T di varie attività, tra le quali anche i laboratori Bell, oggi di proprietà di Lucent Technologies Inc. A seguito delle ristrettezze economiche conseguenti, i Bell Labs furono costretti a cedere in licenza vari gioielli di famiglia, e tra essi anche il marchio Unix, oggi di proprietà del consorzio Open Group. Intanto, il sistema Unix giungeva alla sua versione System V Release 4: questa va considerata come l'implementazione di riferimento per le altre implementazioni commerciali realizzate dalle ditte che appartengono al consorzio: SunOS di Sun Microsystems, AIX di IBM, HP-UX di Hewlett Packard, A-UX di Apple, Xenix di Microsoft, ecc. Alcuni di questi prodotti non sono più in circolazione da anni.
Altre implementazioni simil-Unix, come il sistema BSD della università di Berkley, proseguivano parallelamente la loro strada generando a loro volta nuovi membri della famiglia.
Il progetto GNU. Alla fine degli anni '80 Richard Stallman, ricercatore del MIT a Boston, lancia la sfida per un nuovo sistema operativo open source: il progetto si chiama GNU (gioco di parole che significa "GNU is not Unix") e che punta a realizzare l'ennesima implementazione di Unix. All'inizio degli anni '90 il progetto GNU vede all'attivo un gran volume di software: manca solo il cuore del sistema, cioè il kernel. Su questa mancanza il progetto si arena per un pò.
Il kernel Linux. Nel 1991 Linus Torvalds, studente della facoltà di informatica presso l'università di Helsinky (Finlandia) annuncia di aver realizzato un kernel per processori Intel 386 su piattaforma IBM-PC-compatibile. In omaggio alla tacita convenzione sui nomi, il kernel viene battezzato Linux. Linus sceglie di distribuire liberamente il proprio programma con licenza GNU GPL. Di conseguenza, Linux costituiva il tassello mancante del grande progetto GNU. Il sistema operativo risultante, completo di kernel Linux, compilatore gcc, librerie a programmi applicativi di base assume quindi il nome di sistema operativo GNU/Linux.
Grazie alla popolarità e al basso costo delle macchine sul quale è implementato, GNU/Linux si diffonde rapidamente attraverso la rete Internet. Nascono le distribuzioni Linux, versioni variamente pacchettizzate del sistema GNU/Linux corredate da una quantità di software di altre parti. Oggi si contano decine di distribuzioni diverse realizzate intorno al nucleo centrale costituito dal software GNU/Linux.
Il kernel Hurd. Nella primavera 2002 il progetto GNU porta a compimento anche l'ultimo tassello del progetto, e viene annunciato il completamento del kernel Hurd basato su tecnologia a microkernel, che sarà presto in competizione con il kernel Linux (kernel di concezione monolitica).
Conclusioni
Possiamo affermare che i concetti alla base del sistema operativo Unix sono così efficaci che il modello è stato seguito, copiato e reinterpretato in infinite varianti. Si usa anche dire che chi vuole costruire un nuovo sistema operativo finisce per fare la brutta copia di Unix: anche se forzata, questa affermazione illustra bene quanto i concetti di base di Unix abbiano influenzato il mondo dell'informatica negli ultimi 30 anni.
Sono proprio i concetti fondamentali alla base di Unix e degli altri sistemi operativi similari, che andremo ad affrontare in questo mini-corso introduttivo.
Bibliografia
La letteratura sul sistema Unix e annessi e connessi è sterminata. In realtà più che un sistema operativo stiamo per esplorare un universo, fatto delle sue terminologie, dei suoi usi e costumi, della sua filosofia di utilizzo e programmazione. Ogni lezione riporta alcuni testi di riferimento, libri, articoli, pubblicazioni e specifiche tecniche utili per approfondire gli argomenti trattati. Affronteremo gli argomenti dal punto di vista sistemistico, e ci rivolgeremo ad utenti, installatori e manutentori del sistema.
Alcuni siti di riferimento:
- www.bell-labs.com/history/unix/ - La storia di Unix e dei suoi protagonisti raccontata nel sito dei Bell Laboratories.
- www.opengroup.org - Il sito del consorzio Open Group che possiede il marchio UNIX.
- www.kernel.org - Sito ufficiale dove sono riposti i sorgenti del kernel Linux.
- www.gnu.org - Sito ufficiale del progetto GNU. Le ultime sul kernel Hurd si trovano in www.gnu.org/software/hurd/.
File system: struttura, file e directory, inode, permessi, comandi principali.
1. Login
Lo scopo del login è di autenticare l'utente attraverso un certo dispositivo di accesso (terminale) e di metterlo in condizioni di interagire con il sistema (shell a linea di comando o shell grafica).
Tipi di terminali:
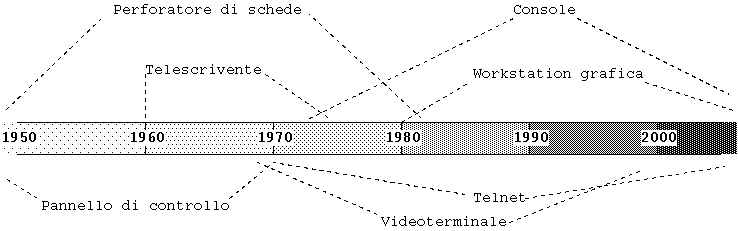
| Tipo | Descrizione | Periodo storico di utilizzo |
|---|---|---|
| Pannello di controllo | Interruttori, bottoni e lucette varie | Anni '50 e primi anni '60 |
| Perforatore di schede | Sistema per la perforazione di schede di Hollerith a 80 colonne, una riga per scheda | Dalla fine dell'800 al 1986 (visto coi miei occhi) |
| Console del computer | Solo i primi mini e personal computer degli anni '70 disponevano di una scheda video e di un monitor, con un formato che poteva andare da 40x24 fino a 80x25 | Dagli anni '70 ad oggi |
| Telescrivente | Tastiera + stampante collegati via seriale a 300 b/s al computer | Anni '60 e '70 |
| Videoterminale | Tastiera + schermo CRT collegati via seriale 300-19200 b/s al computer; il più famoso è il "VT100" di DEC (Data Equipment Corp.): molti programmi terminale di oggi ne supportano l'emulazione | Dagli anni '70 ad oggi |
| Workstation grafica | Ovvero, costoso computer dotato di costoso monitor grafico, sacrificato alla sola funzione di terminale grafico di un computer centrale. Solo alla fine degli anni '80, con l'affermazione del protocollo X Window, sui sistemi Unix è diventato disponibile un sistema per terminale grafico accessibile via rete | Dalla fine degli anni '80 ad oggi |
| Telnet ed emulatore terminale | Console, videoterminale o finestra (xterm) utilizzati per emulare un terminale di un computer remoto accessibile via protocollo IP, più modernamente sostituito dal protocollo SSH crittato | Dai primi anni `60 ad oggi |
2. Eventi conseguenti al login:
- il nome utente e la password vengono confrontati con i dati memorizzati dal computer (per l'esattezza, in /etc/passwd e in /etc/shadow) e, se non corrispondo (nome o password errati) l'accesso viene negato;
- il processo che gestisce il login richiama lo shell scelto dall'utente (con chsh) e riportato in /etc/passwd, ultimo campo;
- la directory corrente viene impostata su /home/pippo, che è lo spazio di lavoro normale dell'utente pippo; nel caso di root, la home dir. è invece /root.
- lo shell (facciamo contro che sia bash) esegue /home/pippo/.bash_profile e /home/pippo/.bashrc in questo ordine (se presenti) e quindi presenta il prompt "$" in attesa di comandi;
- l'utente termina la sessione con il comando "logout" oppure "exit".
3. Info telegrafiche su Bash
- Opera per linee: fintanto che non si preme Return o Enter, nulla viene eseguito.
- Si possono usare i tasti delle frecce sx/dx per posizionare il cursore, Del o CTRL-H per cancellare.
- I tasti freccia-su e freccia-giù per navigare nello storico dei comandi.
- Il tasto "Tab" per l'auto-completamento di comandi e nomi di file.
- Una volta premuto Enter, lo shell scompone la riga in parole: i caratteri separatori validi sono lo spazio e il tabulatore. Due o più spazi valgono come un separatore.
- La prima parola viene considerata come nome di comando, le eventuali altre parole come parametri da passare al comando.
- Per inserire spazi o altri caratteri strani nei parametri, delimitare tali parametri con le virgolette doppie ".
- Sequenze lunghe di comandi si possono mettere in un file di testo esattamente come le si batterebbe da tastiera ed eseguite con il comando
source nomefile
- Come fa Bash a trovare il comando? Si possono usare pathfile assoluti o relativi, altrimenti Bash si basa sul contenuto della variabile d'ambiente PATH (echo $PATH per vederne il valore corrente).
- E' possibile creare propri comandi e metterli ad esempio in /home/pippo/bin; poi conviene aggiungere questo path a quelli predefiniti mettendo in .bashrc:
export PATH=/home/pippo/bin:$PATH
Per vedere subito l'effetto di questo comando, impartirlo anche da prompt, oppure eseguire .bashrc, oppure ri-eseguire il login.
4. File di testo ASCII
Usa 7 bit per byte, quindi l'ottavo bit viene sprecato| 0 | 16 | 32 | 48 | 64 | 80 | 96 | 112 | |
|---|---|---|---|---|---|---|---|---|
| 0 | NUL | DLE | SP | 0 | @ | P | ` | p |
| 1 | SOH | DC1 | ! | 1 | A | Q | a | q |
| 2 | STX | DC2 | " | 2 | B | R | b | r |
| 3 | ETX | DC3 | # | 3 | C | S | c | s |
| 4 | EOT | DC4 | $ | 4 | D | T | d | t |
| 5 | ENQ | NAK | % | 5 | E | U | e | u |
| 6 | ACK | SYN | & | 6 | F | V | f | v |
| 7 | BEL | ETB | ' | 7 | G | W | g | w |
| 8 | BS | CAN | ( | 8 | H | X | h | x |
| 9 | HT | EM | ) | 9 | I | Y | i | y |
| 10 | LF | SUB | * | : | J | Z | j | z |
| 11 | VT | ESC | + | ; | K | [ | k | { |
| 12 | FF | FS | , | < | L | \ | l | | |
| 13 | CR | GS | - | = | M | ] | m | } |
| 14 | SO | RS | . | > | N | ^ | n | ~ |
| 15 | SI | US | / | ? | O | _ | o | DEL |
Osserviamo che la tabella ha 8 colonne per 16 righe, per un totale di 128 caselle e altrettanti simboli: è esattamente quello che ci dobbiamo aspettare con un codice ad 7 bit: infatti 27=128. Il codice decimale di un simbolo si ottiene sommando i numeri in grigio al cui incrocio si trova il simbolo. Ad esempio, il codice ASCII decimale della lettera A è 1+64=65.
Non tutti i simboli producono la scrittura di un carattere sulla carta (o sullo schermo): alcuni codici sono speciali e sono detti codici di controllo. I codici di controllo sono indicati con una sigla a due o tre lettere in corsivo. I codici di controllo occupano le prime 32 posizioni e l'ultima. Non tutti questi codici hanno conservato il significato originario che avevano nelle telescriventi, ma alcuni di essi sì: vediamo i principali usati ancora oggi:
NUL (0) - Il codice di controllo nullo non aveva effetto sulle telescriventi. La libreria standard del C, a fondamento del sistema UNIX e quindi anche di GNU/Linux, lo usa per marcare la fine delle stringhe nella loro rappresentazione in memoria.
BEL (7) - Il codice di controllo che nelle telescriventi azionava il campanello per produrre un sonoro "diiiinnnng". Oggi produce uno stridulo bip emesso dal buzzer piezoelettrico incorporato nei cabinet dei computer. In entrambi i casi serve per attirare l'attenzione dell'operatore su qualche evento inconsueto.
BS (8) - Il back space produceva lo spostamento della testina di stampa della telescrivente a sinistra di un carattere; spesso veniva utilizzato per eseguire il grassetto stampando una lettera, il BS, e quindi di nuovo la stessa lettera sopra la stampata precedente. Incredibile ma vero, viene usato ancora oggi con lo stesso significato: prova a dare il comando man ls | cat -vt: tutti quei ^H sono i caratteri BS usati per rendere il grassetto della man page!
HT (9) - L'horizontal tabulation comandava lo spostamento della testina di stampa all'inizio del successivo campo, esattamente quello che fa oggi sui nostri terminali. La larghezza dei campi è di solito 8 caratteri.
FF (12) - Il form feed produceva lo scorrimento della carta in modulo continuo fino a portare la testina di stampa sulla prima riga del foglio seguente. Oggi produce la cancellazione dello schermo e il posizionamento del cursore in alto a sinistra.
CR (13) - Il carriage return forzava la testina di stampa a scorrere fino al margine sinistro, posizionandosi quindi in corrispondenza del primo carattere della riga. Idem sui videoterminali moderni.
ESC (27) - Il codice di escape ha un pò il ruolo di jolly, e precede tipicamente una sequenza di caratteri che vengono interpretati in modo speciale dalla telescrivente piuttosto che essere stampati. Lesequenze di escape, così come vengono chiamate ancora oggi, sono largamente utilizzate per comandare terminali, stampanti, e come codici generati dalla pressione di certi tasti speciali.
SP (32) - Lo space non è un carattere di controllo, ma semplicemente lo spazio. Si tratta di un carattere "stampabile" come gli altri, con la particolarità che non lascia alcuna traccia sulla carta o sullo schermo, ma ha il solo effetto di spostare la testina di stampa o il cursore.
Per completare questa rapida carrellata sull'ASCII, ricordo le denominazioni più accreditate di alcuni caratteri che si incontrano meno frequentemente ma che appaiono spesso nella documentazione:
# - cancelletto, diesis, number.
& - "e" commerciale, ampersand.
' - accento acuto.
- - meno, minus, hypen.
/ - barra obliqua, slash.
: - duepunti, colon.
; - puntoevirgola, semicolon.
< - minore di, less than.
> - maggiore di, greater than.
@ - chiocciola, chiocciolina, at.
[ - parentesi quadra aperta, left square bracket.
] - parentesi quadra chiusa, right square bracket.
\ - barra obliqua inversa, back slash.
^ - accento circonflesso.
_ - sottolinea, underscore.
` - accento grave.
{ - parentesi graffa aperta, left curly brace.
} - parentesi graffa chiusa, right curly brace.
| - barra verticale, vertical bar.
~ - tilde.
& - "e" commerciale, ampersand.
' - accento acuto.
- - meno, minus, hypen.
/ - barra obliqua, slash.
: - duepunti, colon.
; - puntoevirgola, semicolon.
< - minore di, less than.
> - maggiore di, greater than.
@ - chiocciola, chiocciolina, at.
[ - parentesi quadra aperta, left square bracket.
] - parentesi quadra chiusa, right square bracket.
\ - barra obliqua inversa, back slash.
^ - accento circonflesso.
_ - sottolinea, underscore.
` - accento grave.
{ - parentesi graffa aperta, left curly brace.
} - parentesi graffa chiusa, right curly brace.
| - barra verticale, vertical bar.
~ - tilde.
Sono quelli dove almeno un byte contiene l'ottavo bit "acceso". In questo caso l'associazione tra il codice binario e la rappresentazione grafica del carattere è dato dalle tabelle ISO, la più comunemente usata essendo l'ISO-8859-1; l'ISO-8859-15 prevede anche il carattere Euro. Il file di testo in sè di norma non contiene l'indicazione della tabella ISO da usare, che pertanto deve essere estrapolata per altra via a seconda del tipo di documento (email, HTML, ecc.).
6. File di testo Unicode e UTF-8
L'Unicode prevede 2 byte per carattere, e così può codificare tutti gli alfabeti del mondo, compreso il cinese. Si può visualizzare solo con appositi programmi che prevedono questo formato.
L'UTF-8 usa 7 bit per carattere per codificare l'ASCII, e attiva l'ottavo bit solo quando serve la codifica Unicode. Ogni carattere Unicode viene quindi codificato con un numero variabile di byte che va da 1 a 3. Il vantaggio è che il testo è visualizzabile con un normale text editor, anche se naturalmente i caratteri diversi dall'ASCII potrebbero apparire a casaccio. Per i testi comuni utilizzati in occidente è più compatto perché la maggior parte dei caratteri sono ASCII. Inoltre, l'UTF-8 attraversa indenne come se fosse un normale testo anche i sistemi e i programmi che non supportano Unicode. Per questi motivi l'UTF-8 è molto usato nella posta Internet e nei sistemi Unix.
7. Creare, editare e visualizzare file di testo
Il file di testo è la forma principale di file in Unix: documentazione, file di configurazione, log, sorgenti, script e altri tipi di file sono dei semplici file di testo. Anche PostScript, HTML, XML, DDT, TeX/LaTeX sono testi. Esistono una varietà di text editor, più o meno sofisticati o specializzati:
- vi e vim (vi improved)
E' tra i più antichi vi-sual editor, e tra i più potenti, lo si trova in tutti i SO Unix. Ripidissima curva di apprendimento. - pico
Facile, di apprendimento immediato, non particolarmente sofisticato. - mcedit
E' l'editor default di mc (Midnight Commander). Di uso immediato, molto simile all'EDIT del DOS.
Per visualizzare (senza modificare) un testo ci sono vari modi:
- cat nomefile
- (viewer di mc con F3)
- more nomefile
- less nomefile
Il più sofisticato è "less": avanzamento pagina (spazio), indietro pagina (b = back), inizio (g = go), fine (G), ricerca (/), quit (q).
8. File System
Ogni dispositivo a blocchi formattato, viene visto come una raccolta di inode, ciascuno con un numero che lo individua all'interno di quel dispositivo. Ogni inode contiene questi dati:
- Tipo del file: f, d, c, b, p, s, l
- Codice utente proprietario (user)
Numero che individua un utente, come risulta da /etc/passwd. - Codice gruppo proprietario (group)
Numero che individua un gruppo di utenti, come risulta da /etc/group. - Permessi rwx per l'user
Dicono se un processo appartenente a quell'user può leggere/scrivere/eseguire il file. - Permessi rwx per il group
Dicono se un processo che non appartiene all'user, ma appartiene al group può leggere/scrivere/eseguire il file. - Permessi rwx per gli altri
- Permessi s (suid user), S (suid group) e t (sticky)
(accenno). - Data di ultimo accesso all'inode, modifica dell'inode, modifica del file.
Sono espresse in secondi a partire dal 1970-01-01 00:00 GMT. I comandi come stat e ls possono visualizzare queste date in forma leggibile. - Numero di link a questo inode
Numero di directory che contengono questo inode e di processi che lo stanno usando. Quando questo numero scende a zero, il file viene cancellato in modo irrecuperabile dal sistema. Lo stesso inode può comparire in diverse directory (hard link) e può essere aperto da più processi contemporaneamente. - Lunghezza del file in byte
La lungh. max dipende dal tipo di formattazione. Di norma superiore a 2 GB. - Tabella dei blocchi del file
Elenco dei blocchi che compongono il file.
Esempio:
$ echo ciao > unfile
$ ls -l unfile
-rw-r--r-- 1 pippo users 5 Jul 24 15:27 unfile
$ ln unfile lostesso
$ ls -l unfile lostesso
-rw-r--r-- 2 pippo users 5 Jul 24 15:27 lostesso
-rw-r--r-- 2 pippo users 5 Jul 24 15:27 unfile
.
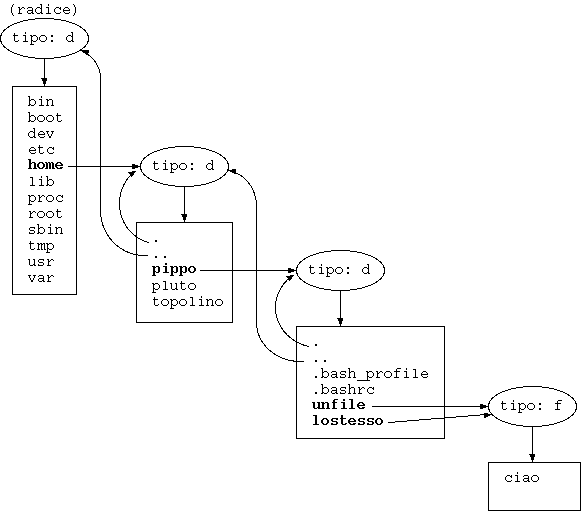
Albero dei file. Gli inode sono rappresentati dagli ovali, mentre i rettangoli rappresentano i file e le directory. Le frecce indicano che l'entrata di una certa directory contiene il numero di inode che corrisponde a un certo inode. Si nota che tutte le dir., eccetto la root, contengono i file "." e ".." che puntano a se stessa e al genitore, rispettivamente. I file
unfile e lostesso contengono l'inode dello stesso file: si tratta di due hard link.9. Directory
Ogni partizione ha una sua dir. radice individuata da un inode, e da cui ramifica il file system. Ogni directory contiene una tabella a due colonne che riporta il numero dell'inode e il nome del file. Esempio:
$ ls -i /
128351 bin
16101 boot
32065 dev
224449 etc
2 home
128354 lib
1 proc
288577 root
288670 sbin
208417 tmp
304609 usr
160321 var
$ stat /usr
File: "/usr"
Size: 4096 Blocks: 8 IO Block: -4611694058606161920 Directory
Device: 302h/770d Inode: 304609 Links: 18
Access: (0755/drwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: Wed Jul 24 19:50:23 2002
Modify: Sat Jul 13 11:35:08 2002
Change: Sat Jul 13 11:35:08 2002
Senza opzioni, il comando ls mostra solo i nomi (la seconda colonna). Con l'opzione -i mostra anche i numeri degli inode. Le altre opzioni del comando ls (v. man ls) fanno stampare tante altre informazioni che vengono estratte dall'inode di ciascun file listato (e quindi ciò comporta un certo lavorio del disco).
Da tutto ciò segue che il nome del file non è una proprietà del file ma è solo un sinonimo del numero di inode e sta scritto nella directory.
Siccome lo stesso inode può avere riferimenti in più dir., ne segue che lo stesso file può assumere nomi diversi.
Non esiste differenza sostanziale tra file e directory: una dir. non è altro che un file di tipo "d" al quale si può accedere in rwx come a ogni altro file. Il significato dei permessi nel caso delle dir. merita un approfondimento:
- r - permesso di lettura, e quindi permesso di vedere l'elenco dei file e i loro nomi
- w - permesso di modificare arbitrariamente la dir., quindi permesso di cancellare qualsiasi file rimuovendone l'entrata corrispondente
- x - permesso di attraversamento: la dir. può apparire nel path di un file anche se la dir. stessa non è leggibile e i file che essa contiene non sono raggiungibili; è possibile invece attraversare la dir. per accedere ad eventuali sotto-dir., permessi permettendo.
Per ogni proprietà di un file, cioè di un inode, esiste un comando apposito per impostarne il contenuto:
Proprietà. Si usa il comando chown (change owner). Esempio:
$ chown pippo:users unfile
In realtà un utente può solo cambiare il gruppo, non l'user, e può farlo solo scegliendo tra i gruppi cui appartiene (v. /etc/group). Naturalmente l'utente root non ha questa limitazione.
Impostare i bit dei permessi. Si usa il comando chmod (change mode). I bit dei permessi voluti si possono impostare usando la base ottale, oppure, in modo più leggibile, usando le lettere u g o (user, group, other) e le lettere r w x s S t (read, write, execution, suid/user, suid/group, sticky). Supponiamo di voler rendere un file leggibile ma non modificabile, al gruppo di utenti cui apparteniamo:
$ chmod u=rw,g=r,o= bollettino-aggiornato-ottobre
Impostare le date. E' possibile modificare ad arbitrio le date di accesso / modifica inode / modifica file usando il comando touch. L'uso più frequente di questo comando è quello di usare questo comando senza parametri: in questo caso cambia tutte le date del file a quella corrente.
Numero di link. Lo si incrementa creando degli hard link al file con il comando ln (link) (v. esempio precedente). Lo si riduce con rm (remove) o con rmdir, che tolgono l'entrata del file dalla directory: dunque rm cancella di sicuro il nome del file, ma non necessariamente cancella anche il file stesso.
Lunghezza del file. Si modifica solo modificando il file stesso.
Tabella dei blocchi del file. Ovviamente, anche questa non è modificabile, pena corruzione del file system!
Cambiare nome al file/dir. Sappiamo che il nome del file non è una proprietà del file, ma un riferimento "letterario" al suo inode presente nella dir. Per cambiare un nome si usa il comando mv (move), che in generale serve anche per spostare i file e le dir. Esempio:
$ mv brutto.nome bel.nome
Copiare un file. Si usa il comando cp (copy). Esempio:
$ cp originale copia
Ovviamente, il file da copiare deve essere leggibile dall'utente, mentre il file di destinazione assumerà proprietà, permessi e dati corrispondenti all'utente che lo ha copiato. Il comando cp ha una infinità di altre opzioni, forse la più importante è -a che preserva invece tutte queste info.
11. Navigare nel file system
Si può usare mc, oppure i tradizionali comandi:
- cd /una/dir
Cambia la dir. corrente. - cd
Torna alla mia home dir. - ls, ln -l, ls -al
Elenco dei file, elenco in forma completa con permessi e date, elenco con anche i file nascosti. - stat nomefile
- / : radice
- /bin : eseguibili (binari) di uso generale
- /boot : kernel e roba per il boot
- /dev : device nodes
- /etc : file di configurazione
- /home : home dirs.
- /home/pippo : home dir.
- /home/pluto : home dir.
- /home/topolino : home dir.
- /lib : librerie e moduli a caricamento dinamico
- /lost+found : blocchi e inode persi
- /proc : file system virtuale del kernel
- /root : home dir. di root
- /sbin : programmi di sistema
- /tmp : file temporanei
- /usr : roba di utilità (docs, programmi, ecc.)
- /var : file di sistema a dimensione variabile (spool di stampa, coda email, mailbox, db, lock, ecc.)
$ locate pass
$ which chmod
Esiste un demone di sistema di nome updatedb, che con una certa periodicità cataloga tutti i file del sistema: il db che esso produce è consultabile con il comando locate.
Il comando which fornisce il pathfile completo del comando indicato seguendo lo stesso algoritmo di bash.
14. Esercizio riepilogativo
Spiegare cosa fanno questi comandi (per quelli che non sono stati descritti qui, come potresti fare?):
bash
cat
cd
chmod
chown
cp
date
exit
less
ln
locate
logout
ls
man
man ascii
mc
more
mv
rm
rmdir
stat
which
Quali dei seguenti pathfile sono dei file? e quali sono delle directory? a cosa servono?
/etc
/etc/passwd
/etc/shadow
/etc/group
/home/pippo
/root
1. Eseguibili (o programmi) e processi
Un eseguibile è un file che possiede il permesso di esecuzione per qualcuno e contiene il codice di un programma, completo delle informazioni necessarie per la sua esecuzione (librerie esterne necessarie, spazio di memoria necessario, informazioni per il debugging, ecc.).
Un processo è l'insieme delle informazioni di gestione, dei dati e del codice caricati in memoria e necessari per la sua esecuzione: tutta questa memoria occupata dal processo si chiama immagine del processo.
Ci possono essere anche parecchi processi che eseguono uno stesso programma: per esempio ci possono essere diversi utenti che eseguono /bin/bash e che stanno usando /bin/ls.
Il kernel esegue a turno tutti i processi che si trovano nello stato di "ready". Ogni processo viene eseguito tipicamente per 0.01 secondi, poi il kernel lo sospende, aggiorna lo scheduler e quindi invoca il processo che risulta averne diritto.
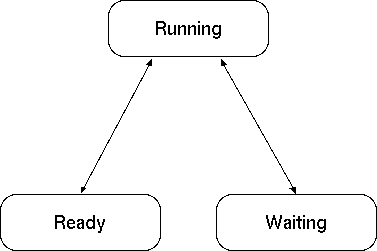
Stati di un processo. Su di un sistema a singolo processore, un solo processo alla volta si trova nello stato Running; scaduto il tempo ad esso concesso, il kernel lo interrompe e lo pone nello stato di Ready. I processi in attesa di eventi esterni, per esempio in attesa di dati dalla tastiera o in attesa di connessioni di rete, vengono posti nello stato di Waiting e risvegliati dal kernel solo quando l'evento arriva. In realtà esistono vari altri stati del processo che qui non abbiamo esaminato, ma si tratta di aspetti non fondamentali per la comprensione degli argomenti di questo corso.
3. Struttura dati di un processo
Le principali informazioni che il kernel mantiene sullo stato di un processo sono:
- PID (process identificator) Esempio: 1234
Numero univoco del processo. - PPID (parent process ident.) Esempio: 1233
Il PID del processo genitore (generalmente si tratta proprio del processo che lo ha avviato). - UID, GID Esempio: pippo, users
Identificativi dell'utente e del gruppo di appartenenza del processo. Generalmente corrispondono alla identità dell'utente che ha avviato il processo. E' ereditario. - Directory di lavoro corrente Esempio: /home/pippo
Può essere impostata liberamente dal processo secondo necessità (in bash lo si fa col comando cd) e viene aggiunto al nome dei file quando questo nome non è assoluto. In altri termini, nella comunicazione tra processo e kernel si evita così di ripetere lunghe stringhe contenenti il path della directory nella quale il processo sta lavorando. E' ereditario. - Maschera dei permessi dei file da NON attivare per default
I permessi da assegnare per default ai file creati dal processo, quando il processo stesso non specifica esplicitamente i permessi da dare. In Bash si imposta con umask (v. man bash). E' ereditario. - Variabili di ambiente Esempio: USER, PATH, ...
Semplice meccanismo per far comunicare i processi tra di loro passando parametri nella forma nome=valore. In Bash si impostano con un comando come:
export NOMEVAR="stringa da assegnare"
Il comando export è necessario perché in sua assenza l'istruzione comporterebbe l'assegnamento di una semplice variabile interna dell'interprete, che perciò non verrebbe ereditata dai processi avviati. Il comando env mostra tutte le variabili d'ambiente correntmente assegnate.
E' ereditaria.
E' ereditaria.
Alcune variabili di ambiente convenzionali riconosciute dai processi e il loro valore assunto per l'utente "pippo":
CLASSPATH=/usr/java/jdk1.3.1_01/jre/lib:.
Dir. delle classi Java (per la JVM).
Dir. delle classi Java (per la JVM).
DISPLAY=:0.0
Server X Window da usare (in questo caso il localhost, display 0, schermo 0). Dice ai processi client dove inviare i comandi di tracciamento e da dove ricevere l'input tastiera+mouse. Impostata per default all'avvio di X Window col comando startx.
Server X Window da usare (in questo caso il localhost, display 0, schermo 0). Dice ai processi client dove inviare i comandi di tracciamento e da dove ricevere l'input tastiera+mouse. Impostata per default all'avvio di X Window col comando startx.
EDITOR=/bin/vim
Text editor preferito. Alcuni programmi fanno riferimento al valore di questa variabile per eseguire il text editor preferito. Ad esempio, il comando crontab -e usa l'editor per editare il proprio file di configurazione.
Text editor preferito. Alcuni programmi fanno riferimento al valore di questa variabile per eseguire il text editor preferito. Ad esempio, il comando crontab -e usa l'editor per editare il proprio file di configurazione.
HOME=/home/pippo
Home dir. dell'utente. Viene impostato dal processo di login.
Home dir. dell'utente. Viene impostato dal processo di login.
HOSTDISPLAY=orso.casa.lan:0.0
Variante di DISPLAY.
Variante di DISPLAY.
PAGER=less --ignore-case
Informa il comando less che intendiamo eseguire le ricerche con / ignorando la differenza tra lettere maiuscole e lettere minuscole, cosa spesso molto utile.
Informa il comando less che intendiamo eseguire le ricerche con / ignorando la differenza tra lettere maiuscole e lettere minuscole, cosa spesso molto utile.
PATH=/home/pippo/bin:/usr/local/bin:/bin:/usr/bin:/usr/X11R6/bin:/sbin:/usr/sbin:/usr/java/jdk1.3.1_01/bin
Nelle directory indicate in questo elenco bash e altri comandi ricercano i comandi da avviare. Il carattere due-punti viene usato per separare gli elementi della lista, e quindi non può apparire nei nomi delle directory.
Nelle directory indicate in questo elenco bash e altri comandi ricercano i comandi da avviare. Il carattere due-punti viene usato per separare gli elementi della lista, e quindi non può apparire nei nomi delle directory.
SHELL=/bin/bash
Il nome dello shell che stiamo usando.
Il nome dello shell che stiamo usando.
USER=pippo
Il nome dell'utente che ha eseguito il login.
Il nome dell'utente che ha eseguito il login.
- Elenco dei file aperti
Dopo il login la situazione è la seguente:
0: la tastiera (stdin)
1: lo schermo (stdout)
2: lo schermo (stderr)
Anche l'elenco dei file aperti è ereditario.
Un processo (parent) crea un altro processo (child) invocando la funzione del kernel fork(). Il kernel crea allora una copia esatta del parent, incluso i dati, lo stack, l'heap, il program counter, ecc. Naturalmente, il processo child ha un PID diverso, e il suo PPID è quello del padre. Tutti i dati del processo padre visti nel paragrafo precedente che sono ereditari, vengono duplicati nel child. Dunque il child ha la stessa identità, la stessa dir. di lavoro, la stessa maschera dei permessi e le stesse variabili di ambiente.
L'unica vera differenza è che la funzione fork() ritorna al padre il PID del figlio, mentre al figlio ritorna zero. L'esecuzione del codice dei due processi prosegue quindi dal punto in cui è avvenuto il forking.
La replicazione è l'unico modo in Unix per creare un nuovo processo, intendendo per nuovo un processo con un altro PID.
Esempio di frammento di programma in liguaggio in prosa che esegue la formattazione e la stampa di un documento. In questo caso l'utente deve aspettare che il programma abbia terminato il suo lavoro di stampa prima di poter proseguire l'editing del documento (pensiamo, ad esempio, che si tratti di un word processor):
procedura Stampa()
{
Formatta
Invia alla stampante
Ritorna
}
In questo secondo esempio, lo stesso programma demanda il lavoro di formattazione e stampa a un processo child:
procedura Stampa()
{
pid = fork()
se pid > 0
io sono il padre:
ritorna immediatamente
altrimenti
io sono il figlio:
Formatta
Invia alla stampante
fine del programma e morte del processo
}
Altro esempio tipico di forking: i daemon process che gestiscono servizi di rete: il padre aspetta la richiesta di connessione e, quando ne arriva una, crea un figlio al quale demanda il lavoro, mentre il padre si rimette subito in ascolto di nuove richieste di connessione (casi tipici: inetd, xinetd, sshd, Apache). In ambiente Unix questa è la strategia seguita da molti programmi server per poter rispondere a interrogazioni multiple contemporanee.
Siccome il forking può richiedere un certo tempo per la duplicazione del processo, alcuni server di rete eseguono il pre-forking in base al carico di lavoro (come fa Apache): il processo padre esegue preventivamente il forking di un certo numero di processi figli, che sono pertanto già pronti a rispondere ad eventuali interrogazioni via rete.
5. Exec
Invocando la funzione del kernel exec(programma, parametri) un processo viene sostituito dal programma indicato: il codice del nuovo programma viene caricato in memoria ed eseguito partendo dall'inizio. Ovviamente ciò comporta la cessazione del programma originario.
Se un programma (come bash) vuole avviare un processo (come ls) senza però morire nell'intento, allora deve eseguire un forking seguito da un exec:
procedura EseguiLS()
{
pid = fork()
se pid > 0
io sono il padre:
1) aspetta la terminazione del figlio, oppure
2) ritorna immediatamente se il processo è stato
avviato con &
altrimenti
io sono il figlio:
exec(/bin/ls, /)
}
Dunque, quando da linea di comando diamo il comando ls, lo shell esegue le seguenti operazioni: genera un processo figlio con fork(); se il PID del processo ritornato dalla funzione fork() è positivo, io sono il padre (cioè lo shell dal quale abbiamo lanciato il comando) e quindi rimango in attesa della terminazione del figlio oppure ritorno immediatamente (se il comando è stato dato con l'& finale); se invece il PID è zero, io sono il figlio, e quindi eseguo con exec() il comando ls.
Ecco i processi attivi sulla mia macchina:
$ ps ax
PID TTY STAT TIME COMMAND
1 ? S 0:04 init [3]
2 ? SW 0:00 [keventd]
3 ? SW 0:00 [kapmd]
4 ? SWN 0:00 [ksoftirqd_CPU0]
5 ? SW 0:00 [kswapd]
6 ? SW 0:00 [bdflush]
7 ? SW 0:00 [kupdated]
8 ? SW 0:00 [mdrecoveryd]
82 ? SW 0:00 [khubd]
591 ? SW 0:00 [eth0]
666 ? S 0:00 syslogd -m 0
671 ? S 0:00 klogd -x
783 ? S 0:00 /usr/sbin/apmd -p 10 -w 5 -W -P /etc/sysconfig/apm-sc
838 ? S 0:00 /usr/sbin/sshd
871 ? S 0:00 xinetd -stayalive -reuse -pidfile /var/run/xinetd.pid
897 ? S 0:00 lpd Waiting
927 ? S 0:00 sendmail: accepting connections
951 ? S 0:00 /usr/sbin/httpd
952 ? S 0:00 /usr/sbin/httpd
970 ? S 0:00 gpm -t imps2 -m /dev/mouse
988 ? S 0:00 crond
1042 ? S 0:00 xfs -droppriv -daemon
1078 ? S 0:00 /usr/sbin/atd
1092 ? S 0:00 login -- salsi
1093 tty2 S 0:00 /sbin/mingetty tty2
1094 tty3 S 0:00 /sbin/mingetty tty3
1095 tty4 S 0:00 /sbin/mingetty tty4
1096 tty5 S 0:00 /sbin/mingetty tty5
1097 tty6 S 0:00 /sbin/mingetty tty6
1100 tty1 S 0:00 -bash
1149 tty1 S 0:00 /bin/sh /usr/X11R6/bin/startx
1161 tty1 S 0:00 xinit /home/salsi/.xinitrc --
1162 ? S 0:09 X :0
1166 tty1 S 0:00 fvwm2
1174 tty1 S 0:00 /usr/X11R6/lib/X11/fvwm2/FvwmButtons 7 4 none 0 8
1176 tty1 S 0:00 netmon -i ppp0 -smooth
1177 tty1 S 0:00 wmmon
1178 tty1 S 0:00 xclock
1323 tty1 S 0:02 gnome-terminal
1330 tty1 S 0:00 gnome-pty-helper
1331 pts/1 S 0:00 bash
1386 pts/1 S 0:01 vim index.html
2494 tty1 S 0:00 gnome-terminal
2501 tty1 S 0:00 gnome-pty-helper
2502 pts/2 S 0:00 bash
4512 tty1 S 0:00 /bin/sh /usr/bin/opera
4513 tty1 S 0:04 /usr/lib/opera/6.02-20020701.3/opera
7081 pts/1 S 0:00 /bin/bash -c (ps ax) < /tmp/salsi/trash/v64790/6 >/tm
7088 pts/1 R 0:00 ps ax
Il comando pstree mette in evidenza l'albero genealogico dei processi, dal quale possimo dedurre chi ha avviato chi:
$ pstree -a -l -n -p -u
init,1)
|-(keventd,2)
|-(kapmd,3)
|-(ksoftirqd_CPU0,4)
|-(kswapd,5)
|-(bdflush,6)
|-(kupdated,7)
|-(mdrecoveryd,8)
|-(khubd,82)
|-(eth0,591)
|-syslogd,666) -m 0
|-klogd,671) -x
|-apmd,783) -p 10 -w 5 -W -P /etc/sysconfig/apm-scripts/apmscript
|-sshd,838)
|-xinetd,871) -stayalive -reuse -pidfile /var/run/xinetd.pid
| |-in.ftpd,8302)
| `-ipop3d,8416)
|-lpd,897,lp)
|-sendmail,927)
|-httpd,951)
| `-httpd,952,apache)
|-gpm,970) -t imps2 -m /dev/mouse
|-crond,988)
|-xfs,1042,xfs) -droppriv -daemon
|-atd,1078,daemon)
|-login,1092)
| `-bash,1100,salsi)
| `-startx,1149) /usr/X11R6/bin/startx
| `-xinit,1161) /home/salsi/.xinitrc --
| |-X,1162,root) :0
| `-fvwm2,1166)
| |-FvwmButtons,1174) 7 4 none 0 8
| |-netmon,1176) -i ppp0 -smooth
| |-wmmon,1177)
| |-xclock,1178)
| |-gnome-terminal,1323)
| | |-gnome-pty-helpe,1330)
| | `-bash,1331)
| | `-vim,1386) index.html
| | `-bash,7231) -c ...
| | `-pstree,7238) -a -l -n -p -u
| |-gnome-terminal,2494)
| | |-gnome-pty-helpe,2501)
| | `-bash,2502)
| | `-less,7193) /usr/local/bin/mypstree
| `-opera,4512) /usr/bin/opera
| `-opera,4513)
|-mingetty,1093) tty2
|-mingetty,1094) tty3
|-mingetty,1095) tty4
|-mingetty,1096) tty5
`-mingetty,1097) tty6
Il comando top fornisce il quadro del carico della macchina, e mostra in cima ("top") i processi più onerosi:
$ top
11:07am up 3:26, 4 users, load average: 0.00, 0.00, 0.00
53 processes: 51 sleeping, 2 running, 0 zombie, 0 stopped
CPU states: 0.6% user, 0.6% system, 0.0% nice, 98.8% idle
Mem: 255908K av, 241824K used, 14084K free, 0K shrd, 2684K buff
Swap: 136512K av, 0K used, 136512K free 102548K cached
PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME COMMAND
1164 root 15 0 266M 10M 3684 S 0.8 4.2 0:44 X
1 root 15 0 480 480 420 S 0.0 0.1 0:04 init
2 root 15 0 0 0 0 SW 0.0 0.0 0:00 keventd
3 root 15 0 0 0 0 SW 0.0 0.0 0:00 kapmd
4 root 34 19 0 0 0 SWN 0.0 0.0 0:00 ksoftirqd_CPU0
5 root 15 0 0 0 0 SW 0.0 0.0 0:00 kswapd
6 root 25 0 0 0 0 SW 0.0 0.0 0:00 bdflush
7 root 15 0 0 0 0 SW 0.0 0.0 0:00 kupdated
8 root 25 0 0 0 0 SW 0.0 0.0 0:00 mdrecoveryd
82 root 15 0 0 0 0 SW 0.0 0.0 0:00 khubd
593 root 15 0 0 0 0 SW 0.0 0.0 0:00 eth0
668 root 15 0 560 560 472 S 0.0 0.2 0:00 syslogd
673 root 15 0 444 444 384 S 0.0 0.1 0:00 klogd
785 root 15 0 480 480 424 S 0.0 0.1 0:00 apmd
840 root 20 0 1228 1228 1020 S 0.0 0.4 0:00 sshd
873 root 18 0 916 916 724 S 0.0 0.3 0:00 xinetd
899 lp 15 0 1132 1132 976 S 0.0 0.4 0:00 lpd
929 root 15 0 1816 1816 1300 S 0.0 0.7 0:00 sendmail
953 root 15 0 1504 1504 1392 S 0.0 0.5 0:00 httpd
954 apache 18 0 1572 1572 1444 S 0.0 0.6 0:00 httpd
972 root 15 0 452 452 396 S 0.0 0.1 0:00 gpm
990 root 15 0 616 616 540 S 0.0 0.2 0:00 crond
1044 xfs 15 0 4376 4376 980 S 0.0 1.7 0:01 xfs
1080 daemon 15 0 524 524 460 S 0.0 0.2 0:00 atd
1094 root 15 0 1184 1184 960 S 0.0 0.4 0:00 login
1095 root 15 0 400 400 344 S 0.0 0.1 0:00 mingetty
1096 root 15 0 400 400 344 S 0.0 0.1 0:00 mingetty
1097 root 16 0 400 400 344 S 0.0 0.1 0:00 mingetty
1098 root 16 0 400 400 344 S 0.0 0.1 0:00 mingetty
1099 root 16 0 400 400 344 S 0.0 0.1 0:00 mingetty
1102 salsi 15 0 1272 1272 1000 S 0.0 0.4 0:00 bash
1144 salsi 16 0 1024 1024 872 S 0.0 0.4 0:00 x
1151 salsi 17 0 1020 1020 868 S 0.0 0.3 0:00 startx
1152 salsi 15 0 520 520 456 S 0.0 0.2 0:00 tee
1163 salsi 15 0 612 612 540 S 0.0 0.2 0:00 xinit
1168 salsi 15 0 2228 2228 1384 S 0.0 0.8 0:00 fvwm2
1176 salsi 15 0 1176 1176 1008 S 0.0 0.4 0:00 FvwmButtons
1177 salsi 15 0 2320 2320 1880 S 0.0 0.9 0:00 xterm
1178 salsi 15 0 656 656 580 S 0.0 0.2 0:00 netmon
I processore Intel 386 e seguenti, i processori Motorola PowerPC, i processori MIPS e altri ancora supportano il concetto di memoria protetta, di segmentazione, e di istruzioni privilegiate.
La memoria protetta è una soluzione hardware adottata dai processori per impedire ai processi di interferire tra di loro andando a scrivere su indirizzi di memoria arbitrari, con conseguenze fatali per il sistema.
La segmentazione è la tecnica hardware/software tipicamente adottata per mantenere traccia dello spazio di indirizzamento riservato a un processo. Per ogni processo, il sistema operativo mantiene una tabella delle aree di memoria cui esso ha accesso; per ogni istruzione eseguita dal processo, il processore verifica che l'accesso alla memoria rispetti la tabella dei segmenti assegnati. Se il processo, per errata programmazione o per deliberata intenzione del programmatore, tenta di accedere ad aree vietate della memoria, il processore interrompe il processo e genera un errore di segmentazione (SEGMENTATION FAULT).
Inoltre, il processore si può trovare di volta in volta in vari stati di esecuzione nei quali determinate istruzioni privilegiate possono o meno essere eseguite dal processo. I processori come l'i386 supportano fino a 4 modalità di privilegio, ma nei sistemi operativi come Unix, Linux e Windows ne vengono utilizzate solo due: la modalità kernel space e la modalità user space:
- Kernel space. Il kernel e i suoi driver lavorano in questa modalità, e quindi possono eseguire anche le istruzioni privilegiate del processore necessarie per indirizzare i dispositivi di I/O e per formulare qualsiasi indirizzo della RAM. Errori di programmazione non comportano l'interruzione del programma, ma tipicamente producono un "KERNEL PANIC".
- User space. In questa modalità operano tutti i processi di utente, root compreso. Il processo gira in un segmento di memoria assegnato dal kernel e non può uscire di lì (pena un "SEGMENTATION FAULT") nè può eseguire istruzioni privilegiate del processore (pena un "ILLEGAL INSTRUCTION"): in entrambi i casi il processo viene interrotto. Il processo può comunicare con i dispositivi di I/O, con la rete e con gli altri processi esclusivamente attraverso il kernel; di conseguenza il kernel ha la possibilità di filtrare le richieste, assegnare le priorità, disciplinare gli accessi concorrenti, distribuire le risorse e controllare i permessi, evitare le interferenze distruttive tra processi diversi.
Sono i file che hanno almeno un bit "x" attivo e sono in formato ELF. Sono prodotti dalla compilazione di qualche linguaggio ad alto livello e contengono codice macchina e informazioni varie per il collegamento dinamico alle librerie. La libreria più importante si chiama libc ed è l'interfaccia tra i programmi che girano nello spazio utente e il kernel.
Esempio di come si può produrre un eseguibile binario a partire da un sorgente C:
salsi@orso, ~ $ echo 'main() { printf("Ciao, mondo!"); }' > ciao.c
salsi@orso, ~ $ cat ciao.c
main() { printf("Ciao, mondo!"); }
salsi@orso, ~ $ cc ciao.c -o ciao
salsi@orso, ~ $ ls -l ciao*
-rwxr-xr-x 1 salsi users 13507 Jul 29 08:50 ciao
-rw-r--r-- 1 salsi users 35 Jul 29 08:49 ciao.c
salsi@orso, ~ $ ./ciao
Ciao, mondo!
salsi@orso, ~ $ file ciao*
ciao: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV),
dynamically linked (uses shared libs), not stripped
ciao.c: ASCII text
salsi@orso, ~ $ ldd ciao
libc.so.6 => /lib/i686/libc.so.6 (0x42000000)
/lib/ld-linux.so.2 => /lib/ld-linux.so.2 (0x40000000)
salsi@orso, ~ $
Sono i file che hanno almeno un bit "x" attivo e sono in formato testo; inoltre, il primi due byte del file devono essere obbligatoriamente la sequenza magica "#!" cui deve seguire il pathfile assoluto dell'interprete, terminato con il carattere di a-capo "Line Feed" (codice ASCII 10) come previsto dalle convenzioni sui file di testo Unix.
Esempio di come si può produrre uno script che visualizza il tradizionale saluto (Bash):
salsi@orso, ~ $ echo "#! /bin/bash" > hello
salsi@orso, ~ $ echo 'echo Hello, world!' >> hello
salsi@orso, ~ $ cat hello
#! /bin/bash
echo Ciao, mondo!
salsi@orso, ~ $ chmod +x hello
salsi@orso, ~ $ ls -l hello
-rwxr-xr-x 1 salsi users 31 Jul 29 08:58 hello
salsi@orso, ~ $ ./hello
Hello, world!
Esempio di script PHP che fa la stessa cosa:
salsi@orso, ~ $ cat bye
#! /usr/bin/php
<? echo "Bye, bye..." ?>
salsi@orso, ~ $ chmod +x bye
salsi@orso, ~ $ ls -l bye
-rwxr-xr-x 1 salsi users 41 Jul 31 08:19 bye
salsi@orso, ~ $ ./bye
X-Powered-By: PHP/4.1.2
Content-type: text/html
Bye, bye...
NOTA: 1 in quest'ultimo esempio in PHP, quando si esegue il programma l'interprete PHP genera in output anche l'header MIME per il protocollo HTTP, siccome per default il PHP suppone di stare rispondendo ad una richiesta CGI. Per evitare la generazione di queste righe basta aggiungere l'opzione -f dopo il nome dell'interprete.
NOTA 2: è possibile scrivere i propri script anche su altri sistemi operativi e poi inviare lo script al sistema Unix, impostare i flag x e infine eseguirlo. Oltre che molto lento e scomodo, questo modo di operare richiede di fare attenzione alla diversa convenzione degli a-capo tra i diversi sistemi operativi:
Unix: LF (10)
DOS, Windows: CR LF (10 13)
Macintosh pre-X: CR
DOS, Windows: CR LF (10 13)
Macintosh pre-X: CR
Cosa succede se si avvia uno script scritto in un file di testo realizzato su di un sistema "straniero" e che usa la convenzione di a-capo di quel sistema?
- FILE DOS, WINDOWS: quando si va ad eseguire il file, il kernel trova che la prima riga contiene:
· #! /bin/bash<CR>
dove <CR> è il codice ASCII CR, che per il kernel di Unix non ha alcun significato particolare; il kernel tenta quindi di eseguire un programma interprete con quel nome, ma, non trovandolo, stampa un enigmatico
: bad interpreter: No such file or directory
Spiegazione: nel messaggio di errore non si legge il nome del "bad interpreter" perché il kernel ha inviato in stampa sul terminale la scritta "/bin/bash<CR>: bad interpreter"; purtroppo, il terminale esegue diligentemente il carriage return CR e riporta il cursore sul margine sinistro, sicché il resto della scritta copre il nome del bad interpreter.
- FILE MACINTOSH: siccome non compare mai il codice LF, risulta che il file contiene una unica riga lunga come tutto il file; naturalmente questa unica riga viene considerata come pathfile dell'interprete generando lo stesso risultato di prima.
Esistono diverse vie, alcune delle quali le abbiamo già viste:
- Parametri sulla linea di comando.
- Variabili di ambiente.
- File. Spesso i programmi sono realizzati per ascoltare dallo stdin e riversare l'output su stdout e i messaggi di errore su stderr. Altri programmi richiedono di specificare tra i parametri della linea di comando su quali file devono operare. Altri programmi ancora fanno riferimento al proprio file di configurazione per sapere su quali file operare.
- Socket Unix e socket Internet. I socket Unix sono una versione più leggera ed efficiente dei socket Internet, ma permettono di comunicare solo tra processi all'interno della stessa macchina. Esempi: il protocollo X Window viene spesso eseguito solo localmente, per cui il client e il server si parlano via socket Unix; PostgreSQL viene spesso usato solo localmente, per cui client e server si parlano via socket Unix. Invece il client FTP (ftp) e il rispettivo server sono programmati per usare solo socket Internet.
- Segnali. Sono semplici numeri compresi tra 1 e 31 che si comunicano a un processo usando il comando kill:
kill -1 7654
invia il segnale 1 (SIGHUP) al PID 7654. Si può omettere il numero di segnale, nel qual caso viene inviato il 15 (SIGTERM). L'elenco di tutti i segnali e il loro significato ed effetto si legge in man 7 signal. Per alcuni segnali il processo può intercettarli e comportarsi come crede; se il processo non specifica diversamente al kernel, esiste una azione default. Nel caso di altri segnali il processo non può ignorarli: se lo fa il kernel lo termina. Per altri segnali ancora, il processo non può intercettarli, e di solito il kernel termina il processo.
Segnale Valore Azione Commento
------- ------ ------ -----------------------------------
SIGHUP 1 t Chiusura del terminale o morte del
processo controllante
SIGINT 2 t Interruzione da tastiera (CTRL-C)
SIGQUIT 3 c Quit da tastiera (CTRL-\)
SIGILL 4 c Istruzione illegale
SIGKILL 9 K Kill signal
SIGSEGV 11 c Violazione della segmentazione
SIGTERM 15 t Richiesta di terminazione
(default signal per kill)
SIGUSR1 10 t User-defined signal 1
SIGUSR2 12 t User-defined signal 2
SIGCHLD 17 i Child fermato o ucciso
SIGCONT 18 Continua se stoppato
SIGSTOP 19 S Stoppa il processo
SIGTSTP 20 s Stop da tastiera (CTRL-S)
SIGBUS 7 c Bus error (bad memory access)
SIGWINCH 28 i Window resize signal
Le lettere nella colonna "Azione" hanno il seguente significato (le lettere maiuscole indicano che il processo non può intercettare il segnale, e l'azione indicata viene perciò eseguita d'ufficio dal kernel):
t Default action is to terminate the process.
i Default action is to ignore the signal.
c Default action is to terminate the process and dump
core.
s Default action is to stop the process.
S Stop the process. Restart with signal SIGCONT.
K Kill the process.
Lezione 3
Rete: configurazione delle interfacce, protocollo Internet, indirizzi e maschere di sottorete, routing, protocollo TCP e principali protocolli basati su di esso.
1. Kernel e networking
Il kernel si occupa di interfacciare le applicazioni con le interfacce di rete, smista e filtra i pacchetti, esegue il firewall, esegue il masquerading, implementa le funzionalità di router e di gateway. Tutte queste funzionalità sono configurabili essenzialmente con i comandi
ifconfig e route, più qualche altro.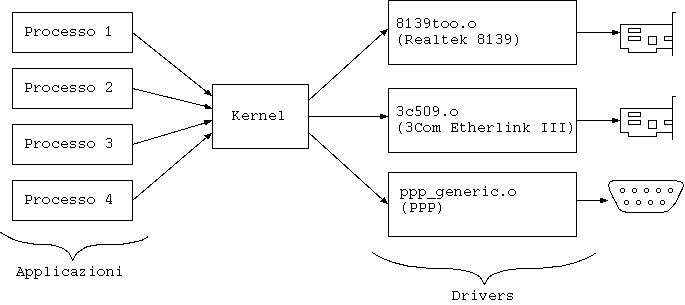
Nei kernel recenti sono inclusi i driver per una gran varietà di dispositivi di rete. Occorre leggere la documentazione del kernel per conoscere tutti i tipi supportati.
I dispositivi PCI sono intrinsecamente plug-and-play, nel senso che se è disponibile un modulo driver per il dispositivo, esso viene caricato automaticamente all'avvio del kernel. Per conoscere i dispositivi trovati bisogna guardare ai messaggi di boot, oppure usare il comando
dmesg. Ad esempio:# dmesg | grep ethSe un dispositivo manca, occorre trovare il modulo driver corrispondente e includerlo nel kernel. Esistono driver in versione sorgente da inserire nel sorgente del kernel e ricompilare, e in versione pacchetto RPM di più immediata installazione.
2. Protocollo IP
Il protocollo IP (Internet Protocol) oggi riconosciuto come "IPv4" (versione 4) è stato definito nella sua forma attuale nel documento RFC 791 nel 1981 (v. www.rfc-editor.org). Si tratta di un protocollo a pacchetti dove ogni nodo della rete ha assegnato un indirizzo univoco a 32 bit. Questi indirizzi sono spesso rappresentati nella forma "quad-byte", dove si riporta il valore di ciascuno dei 4 byte che lo compongono rappresentato in base 10. Questi sono modi alternativi di scrivere lo stesso indirizzo:
00001100001000100011100001001110 (binario)203569230 (decimale)12.34.56.78 (quad-byte)Ogni pacchetto IP contiene il numero di nodo (o indirizzo di nodo) del mittente e del destinatario, ed ogni nodo della rete fa del suo meglio per recapitare il pacchetto verso la destinazione. Trattandosi di una rete, infatti, raramente i due computer che si parlano sono connessi direttamente, per cui i pacchetti sono costretti ad attraversare un numero variabile di nodi prima di arrivare a destinazione.
La maschera di sottorete è uno strumento per decidere il routing dei pacchetti in base all'indirizzo di destinazione. La maschera è un pattern di bit che viene confrontato con i bit dell'indirizzo di destinazione: l'AND logico tra i due valori dà l'indirizzo della sottorete. Esempio:
Destinazione: 00001100001000100011100001001110 ANDMaschera: 11111111000000000000000000000000 = -------------------------------- Risultato: 00001100000000000000000000000000La cosa è forse un pò più chiara se espressa in notazione quad-byte:
Destinazione: 12.34.56.78 ANDMaschera: 255. 0. 0. 0 ------------Risultato: 12.0.0.03. Configurazione dell'interfaccia
Il fatto che il driver di una data interfaccia sia caricato non è sufficiente per il suo corretto funzionamento: bisogna infatti assegnare alla scheda di rete (o quant'altro) un indirizzo di nodo e una maschera di sottorete adatti. Questo lo si fa con il comando
ifconfig (InterFace CONFIGuration):# ifconfig eth0 12.34.56.78che assegna l'indirizzo 12.34.56.78 alla scheda pilotata dal driver eth0 (le eventuali altre schede si chiameranno eth1, eth2, ecc., e i numeri vengono assegnati in base all'ordine in cui sono caricati i driver, per cui non è facilmente prevedibile). La maschera di sottorete usata in questo caso è quella default per un indirizzo del tipo usato nell'esempio, e cioè 255.0.0.0. Se non è quella corretta, allora bisognerà specificare anche questo dato:
# ifconfig eth0 12.34.56.78 netmask 255.255.0.0La maschera di sottorete decide quando il pacchetto deve essere smistato all'interno della rete Ethernet oppure deve andare al gateway.
Per visualizzare lo stato delle interfacce configurate basta dare il comando
ifconfig da solo, eventualmente specificando il nome della interfaccia se si è interessati solo a quella. Ecco la situazione nel mio computer: root@orso, ~ # ifconfigeth0 Link encap:Ethernet HWaddr 00:30:84:9D:86:5D inet addr:10.0.0.1 Bcast:10.0.0.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:4 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:100 RX bytes:0 (0.0 b) TX bytes:240 (240.0 b) Interrupt:9 Base address:0x6f00 lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 UP LOOPBACK RUNNING MTU:16436 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:0 (0.0 b) TX bytes:0 (0.0 b) ppp0 Link encap:Point-to-Point Protocol inet addr:151.26.156.247 P-t-P:151.5.168.56 Mask:255.255.255.255 UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1500 Metric:1 RX packets:4 errors:1 dropped:0 overruns:0 frame:0 TX packets:5 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:3 RX bytes:40 (40.0 b) TX bytes:58 (58.0 b)Per richiamare questi comandi ad ogni riavvio della macchina basta inserirli in
/etc/rc.d/rc.local oppure, meglio, in /etc/rc.d/init.d/network.4. Routing
La tabella di routing permette di gestire in modo abbastanza versatile la logica di routing desiderata. Si tratta di una tabella che si trova dentro al kernel e che è costituita essenzialmente dalle informazioni necessarie per individuare l'interfaccia di rete da usare una volta noto l'indirizzo di destinazione. Per inviare un pacchetto all'indirizzo a.b.c.d, il kernel esamina nell'ordine i valori della colonna "Genmask": viene eseguito l'AND logico dell'indirizzo di destinazione con la genmask e poi il risultato viene : se coincide, il pacchetto viene inviato al driver dell'interfaccia specificato.
La singola interfaccia deve conoscere a sua volta il metodo di routing opportuno per la sua natura. La situazione sul mio computer è questa:
root@orso, ~ # routeKernel IP routing tableDestination Gateway Genmask Flags Ifacebo1ie08u.iunet. * 255.255.255.255 UH ppp010.0.0.0 * 255.255.255.0 U eth0127.0.0.0 * 255.0.0.0 U lodefault bo1ie08u.iun 0.0.0.0 UG ppp0eth0 è l'interfaccia Ethernet per la rete locale, mentre ppp0 è il modem. La situazione è più chiara se mettiamo l'opzione -n che dà gli indirizzi in forma numerica:
root@orso, ~ # route -n
Kernel IP routing tableDestination Gateway Genmask Flags Iface151.5.168.56 0.0.0.0 255.255.255.255 UH ppp010.0.0.0 0.0.0.0 255.255.255.0 U eth0127.0.0.0 0.0.0.0 255.0.0.0 U lo0.0.0.0 151.5.168.56 0.0.0.0 UG ppp0In questo esempio la Genmask dell'ultima riga 0.0.0.0 intercetta tutti gli indirizzi IP che non corrispondono alle sottoreti delle righe precedenti e quindi dirotta i pacchetti verso ppp0 al gateway 151.5.168.56.
Per aggiungere righe nella tabella di routing:
# route add -net 192.168.0.0 netmask 255.255.255.0 eth0# route add -net 192.168.0.0/24 eth0# route add default gw 192.168.0.105Per rimuovere righe nella tabella di routing si usano gli stessi comandi sostituendo "add" con "del".
La tabella di routing viene automaticamente ripulita quando un device viene tolto o disabilitato:
# ifconfig eth0 down# killall pppdLe entrate nella tabella di routing vengono automaticamente ordinate in modo appropriato. Non esiste modo di indicare l'esatta posizione nella quale si vuole inserire una riga, perché questo viene deciso dal kernel sulla base di regole di coerenza della tabella stessa. In generale, le entrate con le genmask più specifiche (cioè con meno bit accesi) vengono per ultime.
Il demone
pppd provvede automaticamente alla sistemazione del routing, salvo diversa esplicita configurazione scelta.Per le schede Ethernet viene impostato automaticamente il routing verso la sottorete default come dedotta dall'indirizzo assegnato, salvo diversa esplicita indicazione.
Gli indirizzi del tipo
10.0.0.0 - 10.255.255.255 (10/8 prefix)172.16.0.0 - 172.31.255.255 (172.16/12 prefix)192.168.0.0 - 192.168.255.255 (192.168/16 prefix)per convenzione non sono utilizzati in Internet ma vengono riservati ad uso interno delle reti locali (RFC 1918).
Per richiamare questi comandi ad ogni riavvio della macchina bisogna inserirli in uno dei file citati al paragrafo precedente.
5. Protocollo TCP/IP (TCP over IP)
Viene descritto nell'RFC 793: basato su IP, il TCP permette di stabilire canali di comunicazione tra un processo residente su di una macchina e un altro processo su di un'altra macchina (o anche sulla stessa, naturalmente). I diversi canali di comunicazione contemporanei vengono individuati da un numero di porta a 16 bit. Il computer che inizia la comunicazione è il client, mentre quello che rimane in attesa della richiesta di collegamento si chiama server.
L'insieme di numeri di nodo del client e del server, e dei numeri di porta TCP del client e del server, sono quattro numeri che costituiscono un socket pair Internet o, brevemente, socket pair. Grazie al concetto di socket pair vari computer stabiliscono vari canali di comunicazione senza rischio che i pacchetti TCP vengano confusi.
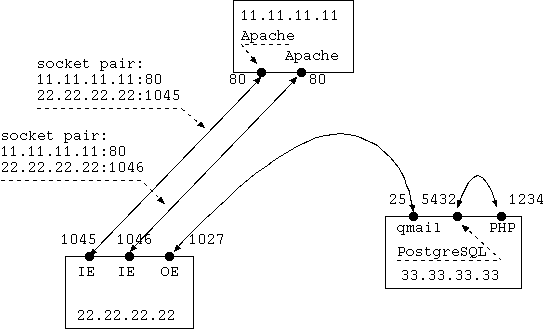
Canali TCP e socket pair. I rettangoli rappresentano i computer sulla rete Internet, mentre i pallini neri rappresentano i socket TCP e riportano il numero della porta assegnata. Il computer 11.11.11.11 sembra essere un server WEB con installato Apache. Il computer 22.22.22.22 ha attivato due canali TCP con Internet Explorer, e contemporaneamente sta inviando posta con Outlook Express verso il computer 33.33.33.33. Quest'ultimo computer sta anche eseguendo un programma PHP che accede al DB PostgreSQL attraverso un canale TCP. I numeri di porta come 25 e 80 sono standard, mentre gli altri numeri di porta hanno l'unico vincolo di essere univoci sul computer dove risiedono.
Mentre il numero di porta utilizzato dal client di norma viene assegnato a caso (basta che sia univoco tra tutte le porte TCP correntemente usare dal client), il numero di porta del server deve essere noto. Esistono perciò delle convenzioni sui numeri porta assegnati riportate nell'RFC 1700. Un estratto di tale documento lo si trova nel file
/etc/services: si tratta di una tabella che mappa i nomi assegnati alle porte convenzionali usate dai server per il protocollo TCP e per l'UDP (di cui non abbiamo parlato qui). Questa tabella serve ad alcuni comandi per poter visualizzare i numeri di porta in forma simbolica, anziché in forma numerica. Tuttavia, è bene ricordare alcuni numeri di porta TCP importanti, da sapere a memoria:25 SMTP
110 POP-3 80 HTTP443 HTTPS20,21 FTP 22 SSH23 Telnet
Sul protocollo TCP sono basati i principali protocolli di livello superiore per la posta elettronica, per il WEB, ecc. Li vedremo nel seguito per mezzo di esempi.
6. Impostare nome e dominio della macchina
# hostname www# domainname azienda.it7. Resolver
Ogni processo che necessita della risoluzione dei nomi di dominio (compresi i programmi server) fa uso della libreria di sistema detta resolver. In questa libreria ci sono le funzioni che permettono la conversione da nome di dominio (es.
www.azienda.it) in numero di nodo (es. 11.11.11.11).La risoluzione statica la fa con il file
/etc/hosts:$ cat /etc/hosts127.0.0.1 localhost.localdomain localhost10.0.0.1 orso.casa.lan orso10.0.0.2 castoro.casa.lan castoro10.0.0.3 emulo.casa.lan emuloLa risoluzione dinamica via servizio DNS la fa in base al contenuto del principale file di configurazione del resolver
/etc/resolv.conf, il cui contenuto tipico potrebbe essere questo:option rotatenameserver 193.70.192.25nameserver 193.70.152.25La riga delle opzioni dice solo di utilizzare i due nameserver indicati a rotazione, in modo da bilanciare il carico sui DNS. Si possono indicare fino a tre DNS.
ATTENZIONE! il file di configurazione viene letto solo la prima volta che il processo chiama una delle funzioni del resolver, tipicamente all'avvio del processo stesso. Nel caso dei programmi server, se occorre modificare il resolver, dopo bisogna anche riavviare i programmi che lo usano.
8. Diagnostica
Scoprire cosa fanno e come si possono usare i comandi seguenti:
pingtraceroutelsof -ipstreetcpdump -i eth0 -s 65535 -l -nn -q -t -x -X9. Telnet come chiave inglese del TCP
Il client telnet implementa essenzialmente il protocollo telnet che dialoga sulla porta TCP 23 del server. Tuttavia lo si può usare come strumento grezzo per parlare TCP su qualsiasi porta, basta indicare il numero della porta voluta e prepararsi a parlare il protocollo di livello superiore direttamente con il server. Siccome i protocolli di livello superiore basati su TCP sono per lo più orientati alla linea, il telnet è perfetto per questo scopo.
Per fare gli esperimenti che seguono raccomando di utilizzare un client telnet adeguato: quello default su Linux va bene, su Windows usare Putty o Teraterm.
10. Leggere la posta (POP-3, RFC 1939)
In questo esempio di sessione interattiva, genero un paio di email di prova e quindi le vado a leggere con il protocollo POP-3. Il server in questione è la mia stessa macchina sulla quale ho installato gli opportuni programmi. Come al solito, le righe evidenziate in grassetto sono quelle che ho scritto io, mentre le altre sono le risposte del computer e del programma server POP-3.
$ echo "body messaggio 1" | mail salsi -s "oggetto 1" $ echo "body messaggio 2" | mail salsi -s "oggetto 2" $ telnet localhost 110Trying 127.0.0.1...Connected to localhost.localdomain.Escape character is '^]'.+OK POP3 localhost.localdomain v2000.69rh server readyuser salsi
+OK User name accepted, password pleasepass pippo
+OK Mailbox open, 2 messagesstat
+OK 2 702list
+OK Mailbox scan listing follows1 3512 351.retr 1
+OK 351 octetsReturn-Path: <salsi@casa.lan>Received: (from salsi@localhost) by casa.lan (Sendmail/3.14) id fBLCt1b01993 for salsi; Fri, 21 Dec 2001 13:55:01 +0100Date: Fri, 21 Dec 2001 13:55:01 +0100From: "U.Salsi" <salsi@casa.lan>Message-Id: <200112211255.fBLCt1b01993@casa.lan>To: salsi@casa.lanSubject: oggetto 1Status: body messaggio 1.dele 1
+OK Message deletedquit
+OK SayonaraConnection closed by foreign host.Un altro comando interessante del protocollo POP-3 è TOP: TOP 12 10 mostra le prime 10 righe del messaggio n. 12. Utile per visionare messaggi immmmensi, prima di deletarli...
11. Inviare la posta (SMTP, RFC 2821)
In questo esempio uso il protocollo SMTP per inviare un email. Il server utilizzato è quello di Libero di Infostrada. Come al solito, le righe evidenziate in grassetto sono quelle che ho scritto io, mentre le altre sono quelle generate dal computer e dal server SMTP.
$ telnet mail.libero.it smtpTrying 195.123.94.65...Connected to localhost.localdomain.Escape character is '^]'.220 smtp3.libero.it ESMTP Service (6.0.032) readyHELO localhost
250 smtp3.libero.itMAIL FROM:<umberto-salsi@libero.it>
250 MAIL FROM:<umberto-salsi@libero.it> OKRCPT TO:<tizio@qualcosa.it>
250 RCPT TO:<tizio@qualcosa.it> OKRCPT TO:<caio@qualcosaltro.it>
250 RCPT TO:<caio@qualcosaltro.it> OKDATA
354 Start mail input; end with <CRLF>.<CRLF>Date: Wed, 17 Aug 2002 21:19:45 CETFrom: Umberto Salsi <umberto-salsi@libero.it>To: tizio@qualcosa.it, caio@qualcosaltro.itSubject: Salve! Sto provando con l'SMTP. Ciao,- Umb.
250 <3C0D5E3F005FC9EA> Mail acceptedQUIT
221 smtp3.libero.it QUITConnection closed by foreign host.Il messaggio deve rispettare le specifiche RFC 2822.
12. Protocollo WEB (HTTP, RFC 2616)
Vedere la home page di www.qualcosa.it usando telnet come browser WEB:
$ telnet www.qualcosa.it 80Trying 12.34.56.78...Connected to www.qualcosa.it.Escape character is '^]'.GET / HTTP/1.0
HTTP/1.1 200 OKDate: Wed, 21 Aug 2002 21:33:20 GMTServer: Apache/1.3.19 (Unix) (Red-Hat/Linux)Last-Modified: Mon, 17 Aug 2002 08:55:23 GMTETag: "fa7b-43-3c146a6b"Accept-Ranges: bytesContent-Length: 67Content-Type: text/html <html><body>...</body></html>Connection closed by foreign host.
13. Configurazione
Quadro delle tipiche implementazioni dei protocolli citati e i file di configurazione usati. Configurare il server consiste nel modificare opportunamente il file di configurazione (con un text editor) e quindi riavviare il server con il comando indicato| Servizio | Programma | File di config. | Per avviare/fermare |
|---|---|---|---|
| Telnet | telnetd | (nessuno) | (avviato da inetd (v. /etc/inetd.conf) o da xinetd (v. /etc/xinetd.conf) |
| SSH | sshd | /etc/ssh/sshd_config | Programma stand-alone da invocare come sshd nel file /etc/rc.d/rc.local, oppure si usa service sshd start|stop|restart|status, a seconda del packaging. |
| SMTP | sendmail | /etc/sendmail.cf | service sendmail start|stop|restart|status |
| POP-3 | imap | (nessuno) | (avviato da inetd (v. /etc/inetd.conf) o da xinetd (v. /etc/xinetd.conf) |
| HTTP | Apache | /etc/httpd/conf/httpd.conf | service httpd start|stop|restart|status |
14. Domande
- Come cambiano le cose se il server SMTP è Sendmail, piuttosto che Qmail, MS Exchange, ecc.?
- Come cambiano le code se il server WEB è Apache, piuttosto che MS IIS, IBM Websphere, Sun Iplanet?
C.Hunt, "TCP/IP Network Administration", O'Reilly 1998
0791 Internet Protocol. J. Postel. Sep-01-1981. (Format: TXT=97779
bytes) (Obsoletes RFC0760) (Also STD0005) (Status: STANDARD)
0793 Transmission Control Protocol. J. Postel. Sep-01-1981. (Format:
TXT=172710 bytes) (Updated by RFC3168) (Also STD0007) (Status:
STANDARD)
0854 Telnet Protocol Specification. J. Postel, J.K. Reynolds.
May-01-1983. (Format: TXT=39371 bytes) (Obsoletes RFC0764) (Also
STD0008) (Status: STANDARD)
1700 Assigned Numbers. J. Reynolds, J. Postel. October 1994. (Format:
TXT=458860 bytes) (Obsoletes RFC1340) (Also STD0002) (Status:
STANDARD)
1918 Address Allocation for Private Internets. Y. Rekhter, B.
Moskowitz, D. Karrenberg, G. J. de Groot, E. Lear. February 1996.
(Format: TXT=22270 bytes) (Obsoletes RFC1627, RFC1597) (Also BCP0005)
(Status: BEST CURRENT PRACTICE)
1939 Post Office Protocol - Version 3. J. Myers, M. Rose. May 1996.
(Format: TXT=47018 bytes) (Obsoletes RFC1725) (Updated by RFC1957,
RFC2449) (Also STD0053) (Status: STANDARD)
2616 Hypertext Transfer Protocol -- HTTP/1.1. R. Fielding, J. Gettys,
J. Mogul, H. Frystyk, L. Masinter, P. Leach, T. Berners-Lee. June
1999. (Format: TXT=422317, PS=5529857, PDF=550558 bytes) (Obsoletes
RFC2068) (Updated by RFC2817) (Status: DRAFT STANDARD)
2821 Simple Mail Transfer Protocol. J. Klensin, Editor. April 2001.
(Format: TXT=192504 bytes) (Obsoletes RFC0821, RFC0974, RFC1869)
(Status: PROPOSED STANDARD)
2822 Internet Message Format. P. Resnick, Editor. April 2001. (Format:
TXT=110695 bytes) (Obsoletes RFC0822) (Status: PROPOSED STANDARD)
Nessun commento:
Posta un commento